项目简介
基于浪潮AI station平台,解决 AI 软硬件交付一体化问题,在模型开发、训练、部署过程中遇到的效率瓶颈和资源管理难题,经彭总提议启动"AI Studio"项目。本项目旨在基于成熟的开源AI studio平台进行二次开发,快速构建一个符合我司特定需求的、统一的 AI 工作平台。
核心目标:
- 提升效率: 提供统一的 Jupyter、Web Shell 环境,简化开发调试。
- 自动化流程: 实现任务编排,自动化模型训练、评估等复杂流程。
- 优化资源: 实现 GPU 等核心资源的灵活调度与精细化管理,提高利用率。
- 数据洞察: 提供资源监控与使用报表,支撑成本核算与优化决策。
- 支持k8s设施: 对接 Kubernetes 集群、NFS 存储和 InfiniBand 网络。
开发策略:
- 后端开发 + AI 辅助: 由我(熟悉 K8s、后端开发)负责主要开发 + 一个后端辅助开发同事 + 借助 Cursor、ChatGPT/Gemini 等 AI 工具加速编码、调试和文档工作。
- 时间周期: 预计 4 -5个月完成核心功能开发与上线。
- 成本效益: 充分利用开源社区成果,极大降低自研成本和时间投入。
功能优先级: GPU 调度 > 任务编排 > Jupyter > 其他
可行性分析
基于成熟开源项目进行二次开发,是构建我们 AI Studio 平台最高效、风险可控的路径。
技术可行性
- 基础架构成熟: 基于 Kubernetes (K8s) 集群,为部署 K8s 原生的 AI station 平台提供了坚实基础。
- 核心功能覆盖: 现有的顶级开源 AI station 项目(如 Kubeflow)已包含大部分核心需求(Jupyter、任务编排、GPU 支持、账号管理等),二次开发主要聚焦于定制、集成和优化。
- 开发者能力匹配: 熟悉 K8s 运维与开发*2,能够承担基础平台的部署、配置和二次开发工作。
- AI 工具赋能: 利用 AI 编程助手能显著提高单人开发效率,处理代码生成、问题排查、文档撰写等任务,使得 4-5 个月周期成为可能。
优势 (Advantages)
- 开发速度快: 大幅缩短研发周期,避免"重复造轮子"。
- 成本效益高: 显著降低研发投入,主要成本在于开发人力和少量云资源。
- 功能起点高: 直接获得业界验证的成熟功能,稳定性有保障。
- 社区支持强: 可利用活跃的开源社区资源解决技术难题。
- 专注核心定制: 可将精力集中在最符合我们业务需求的定制化功能上。
风险与应对 (Risks)
- 开源项目复杂度: Kubeflow 等平台本身较复杂,学习曲线陡峭。(应对:聚焦核心组件,利用 AI 工具辅助理解和调试)
- 集成难度: 将我们特定的需求(如精细化报表、特定 IB 网络配置)与开源平台融合可能遇到挑战。(应对:优先保障核心功能,复杂集成点分阶段实现,保持配置灵活性)
- 上游版本依赖: 基础平台的更新可能带来兼容性问题。(应对:选择 LTS 或稳定版本,谨慎跟进升级,做好兼容性测试)
- 人力风险: 开发属于兼职开发,可能成为瓶颈。(应对:充分利用 AI 工具,文档记录清晰,核心功能优先,争取内部或临时资源支持)
- 定制化维护成本: 过度定制可能导致后续维护困难。(应对:遵循开源项目扩展规范,代码模块化,减少对核心代码的侵入式修改)
竞品分析:选择最佳开源基石
我对比了几个主流的开源 AI station 平台,以选择最适合二次开发的基石:
| 评估维度 | Kubeflow | MLRun (Iguazio) | Flyte (Lyft/Union AI) | "AI Studio"定位 (基于 Kubeflow 定制) |
|---|---|---|---|---|
| 核心功能覆盖 (Jupyter, 编排, GPU, 账号, 资源, NFS/IB*) |
非常全面,组件化提供几乎所有需求功能。*IB需K8s配置 | 较全面,强项在 Serverless Function 和 Feature Store 集成。*IB需K8s配置 | 任务编排是强项,类型安全,可复现性好。其他功能需集成。*IB需K8s配置 | 继承 Kubeflow 全面功能,并针对性强化 GPU 调度可视化、资源报表和易用性。 |
| 社区活跃度 | 非常高,Google 发起,CNCF 孵化项目,贡献者众多。 | 中等,主要由 Iguazio 推动,社区在增长。 | 高,CNCF 毕业项目,社区活跃,文档优秀。 | 受益于 Kubeflow 庞大社区,降低技术支持风险。 |
| 部署复杂性 | 高,组件多,依赖复杂,有多种发行版。 | 中等,相对 Kubeflow 可能稍简单,但仍需 K8s 专业知识。 | 中等,核心部署相对清晰,但整体生态集成也需投入。 | 初期复杂性同 Kubeflow,但通过定制简化常用操作入口。 |
| 扩展性/定制化 | 高,微服务架构,API 丰富,适合二次开发和定制。 | 高,设计考虑扩展性,提供 SDK 和 API。 | 高,插件化设计,易于扩展后端和添加新类型。 | 利用 Kubeflow 的高扩展性,按需定制 UI、调度策略和报表。 |
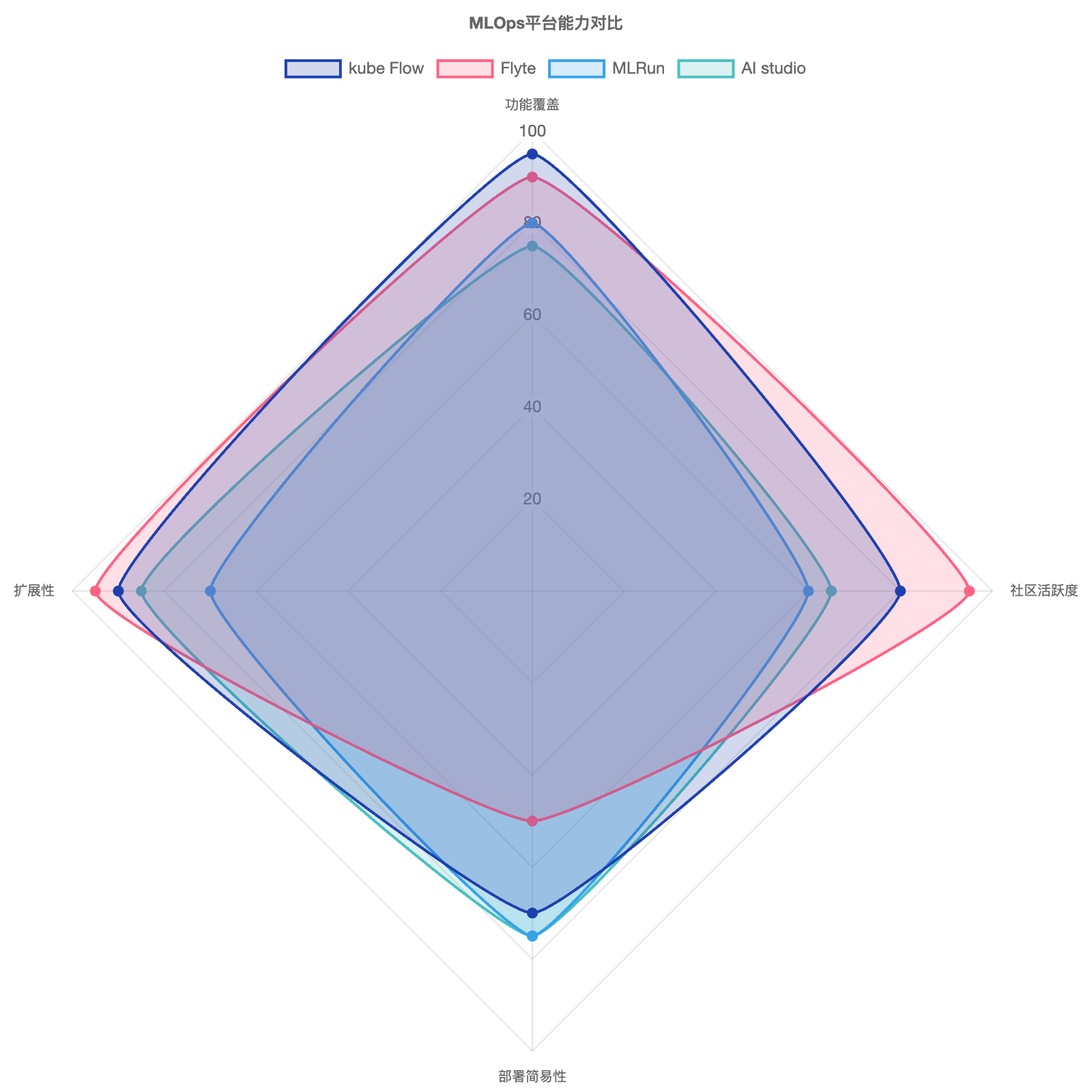
结论: Kubeflow 在功能全面性、社区支持和扩展性方面综合最佳,虽然部署复杂,但其 K8s 原生特性、对我们所需功能的广泛覆盖使其成为二次开发的最优选择。AI Studio 将在其基础上进行精简和定制,扬长避短。
详细二次开发项目计划
以下是基于 Kubeflow 进行二次开发的详细计划,已考虑功能优先级和 AI 工具辅助:
环境配置要求
| 配置项 | 要求 |
|---|---|
| 推荐操作系统 |
Ubuntu LTS (22.04, 20.04) 优势:
|
| Docker 版本 | ≥ 19.03 |
| Kubernetes 版本 | 1.24 ~ 1.28 |
| kubectl 版本 | 1.24 |
| 存储要求 | cfs/ceph 需挂载到每台机器的 /data/k8s/ |
| 单机磁盘容量 | ≥ 300G(仅做镜像容器的存储,容量要求不大) |
| 控制端配置 | CPU ≥ 16核,内存 ≥ 32G |
| 任务端配置 | CPU ≥ 32核,内存 ≥ 64G |
| 网络要求 | 需要科学上网 ssh端口需开放给:113.200.54.58/120.192.215.66 |
任务分解与每周排期 (预计 18 周)
| 周次 | 核心任务 | 主要产出/目标 | 优先级/涉及功能 |
|---|---|---|---|
| W1-W2 | 需求确认、环境准备 & Kubeflow 基础部署 | 明确需求目标、K8s 集群就绪 (GPU/NFS/IB 验证), 选用稳定版 Kubeflow 核心组件安装成功,基础访问验证。 | 基础设施 |
| W3-W4 | 核心组件熟悉 & 认证集成 | 深入理解 Kubeflow Notebooks, Pipelines, RBAC (权限)。 | 账号管理, Jupyter, 任务编排 |
| W5-W6 | GPU 调度验证与定制调研 | 确保 Pod 能请求并使用 GPU。调研 K8s Device Plugin (Nvidia/Ascend*) 和 Kubeflow 调度策略。调研监控指标。(*若涉及昇腾) | GPU 调度, 资源管理 |
| W7-W8 | 任务编排 (Pipelines) 实践 | 能通过 UI 或 SDK 定义、运行、监控简单的训练 Pipeline (至少包含数据处理、训练、评估步骤)。验证 NFS 访问。 | 任务编排, NFS/IB(依赖:集群中至少有2台具有RDMA网络的GPU实例。) |
| W9-W10 | Jupyter & Web Shell 集成优化 | 确保 Jupyter 环境稳定易用,镜像管理。集成或优化 Web Shell 访问功能 (如集成到 Notebook 或提供独立入口)。 | Jupyter, Web Shell |
| W11-W12 | GPU 调度 & 资源管理定制开发 (前端/后端) | 开发或定制 UI 界面,简化 GPU 选择、监控。实现基本的资源配额展示或限制 (基于 Namespace)。 | GPU 调度, 资源管理 |
| W13-W14 | 资源监控与报表开发 (初步) | 集成 Prometheus/Grafana (若 Kubeflow 未带) 或利用其数据。开发基础的 GPU/CPU/内存使用率报表 (按用户/项目)。 | 资源监控报表 |
| W15 | 整合测试 & 性能调优 | 端到端测试核心流程。压力测试关键组件。修复 Bug。 | 整体功能 |
| W16-W18 | 文档编写 & 内部发布 (Alpha) | 编写用户手册、运维文档。部署到预生产环境,进行小范围内部试用。 | 文档, 部署 |
项目风险评估
- 技术难点超预期: 特别是 IB 网络深度集成或复杂调度策略定制。(应对:保持方案灵活性,优先保障核心网络可达和基本调度,复杂功能放后期迭代)
- AI 工具效率未达预期: 过分依赖 AI 可能导致进度延误。(应对:合理分配时间,复杂逻辑部分仍需人工深度参与,定期评估 AI 辅助效果)
- 需求蔓延: 项目过程中新增非核心需求。(应对:严格管理需求范围,聚焦本期核心目标,新需求放入后续迭代计划)
- 开源组件 Bug: 遇到基础平台或依赖库的 Bug。(应对:积极查找社区解决方案或 Workaround,必要时向上游报告)
总结与战略价值
通过"AI Studio"项目,我们能在 4-5 个月内,以极具竞争力的成本(基于开源二开方案),构建一个强大的、定制化的 AI station 平台。这将:
- 显著提升 AI 研发效率: 缩短模型从开发到上线的周期。
- 最大化资源价值: 特别是昂贵的 GPU 资源,通过精细化调度和监控提高利用率,降低成本。
- 赋能 AI 团队: 提供统一、易用的工作环境,让研究员和工程师更专注于算法创新。
- 奠定未来基础: 为后续更复杂的 AI station 功能(如模型服务、特征存储等)打下坚实基础。
本项目技术可行性高,风险可控,战略价值明确。借助开源力量和 AI 工具,我们有信心达成目标,为公司的 AI 发展注入强大动力!